Key reinforcement learning terms and definitions — searchable.
Actor-CriticArchitecture combining a policy network (actor) that selects actions and a value function network (critic) that evaluates them.
PolicyMapping from states to actions — the agent's learned strategy for decision-making.
Reward FunctionSignal defining the goal — scalar feedback the agent aims to maximise over time.
Value FunctionEstimate of expected cumulative future reward from a given state or state-action pair.
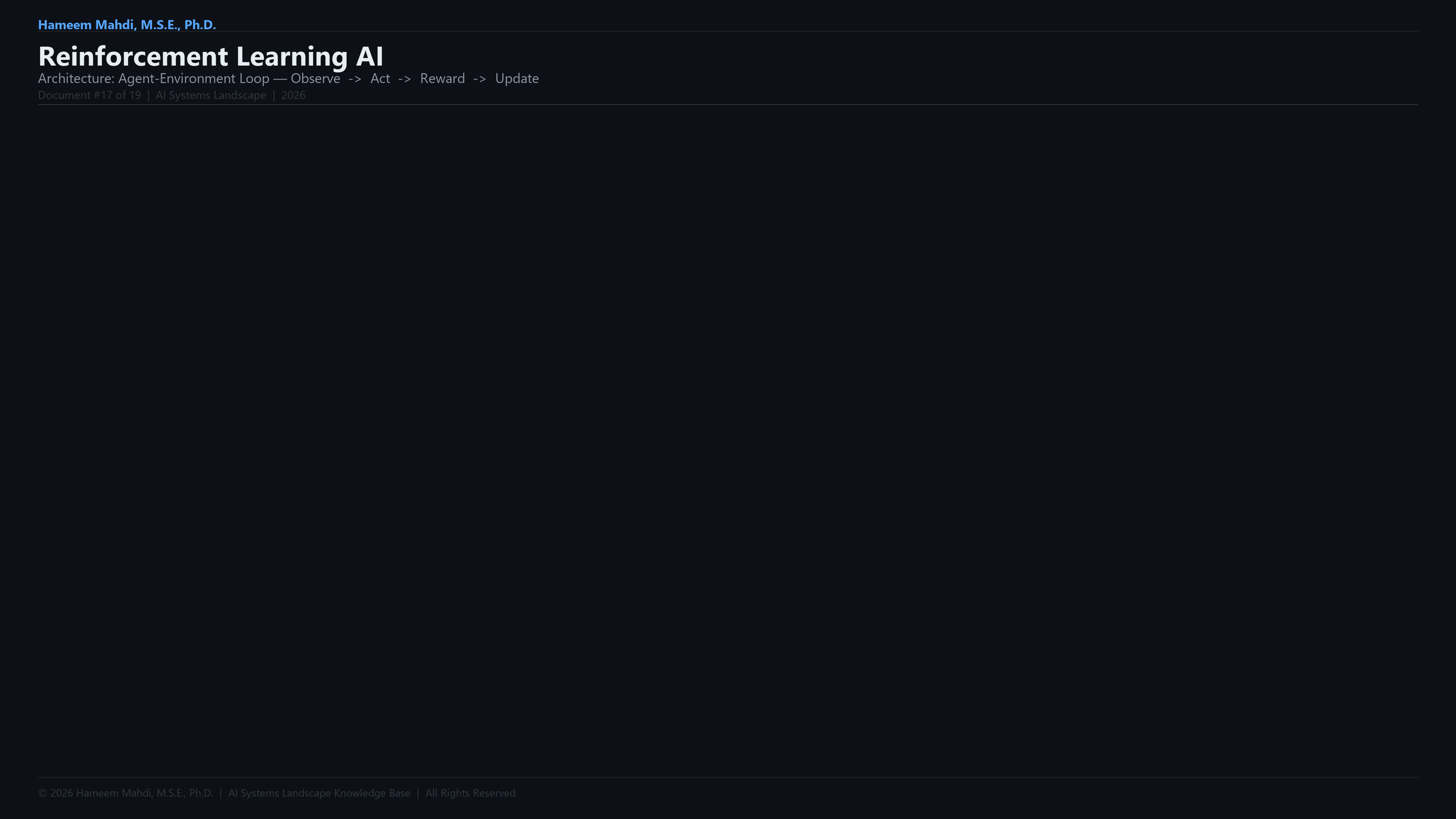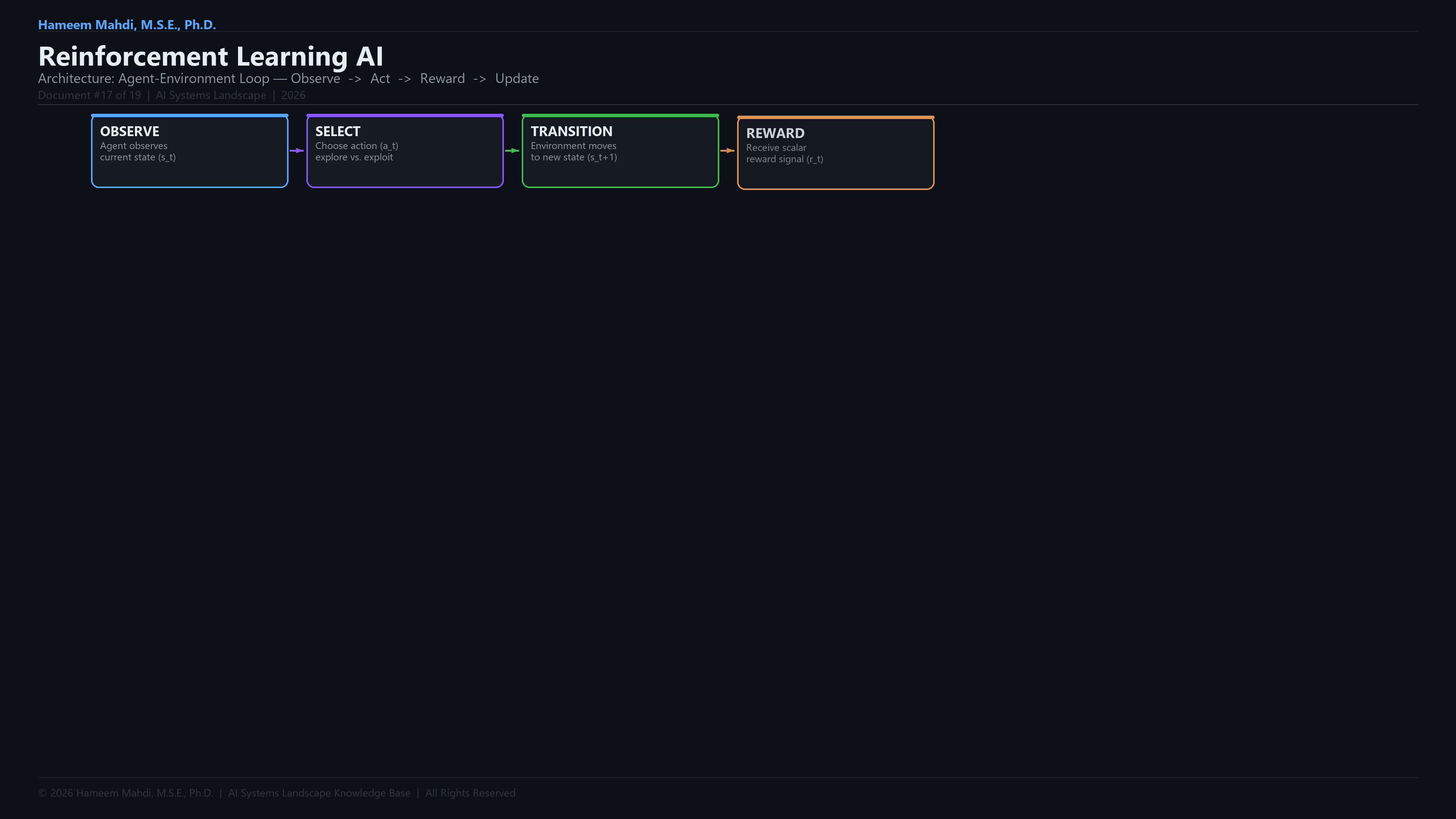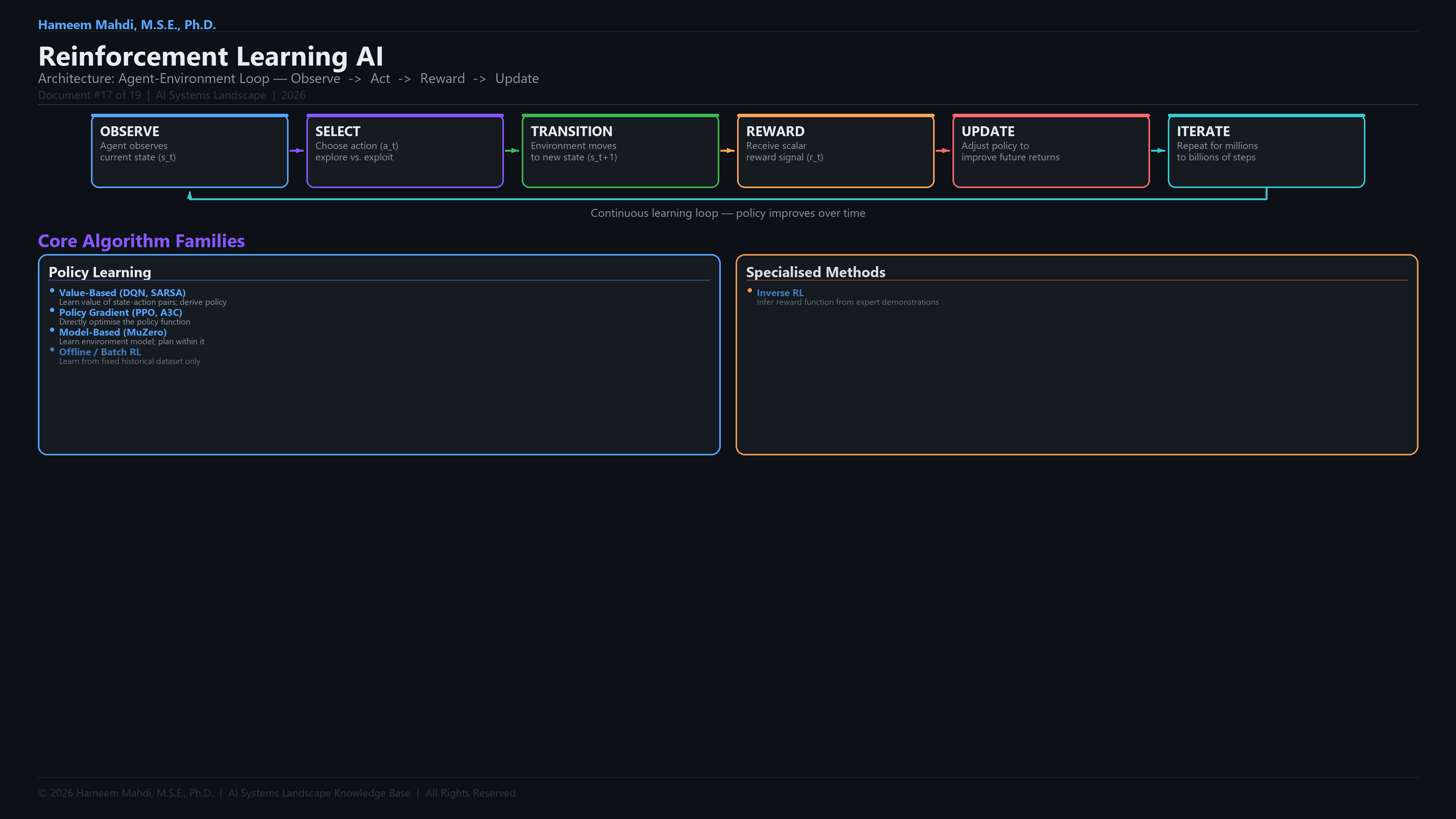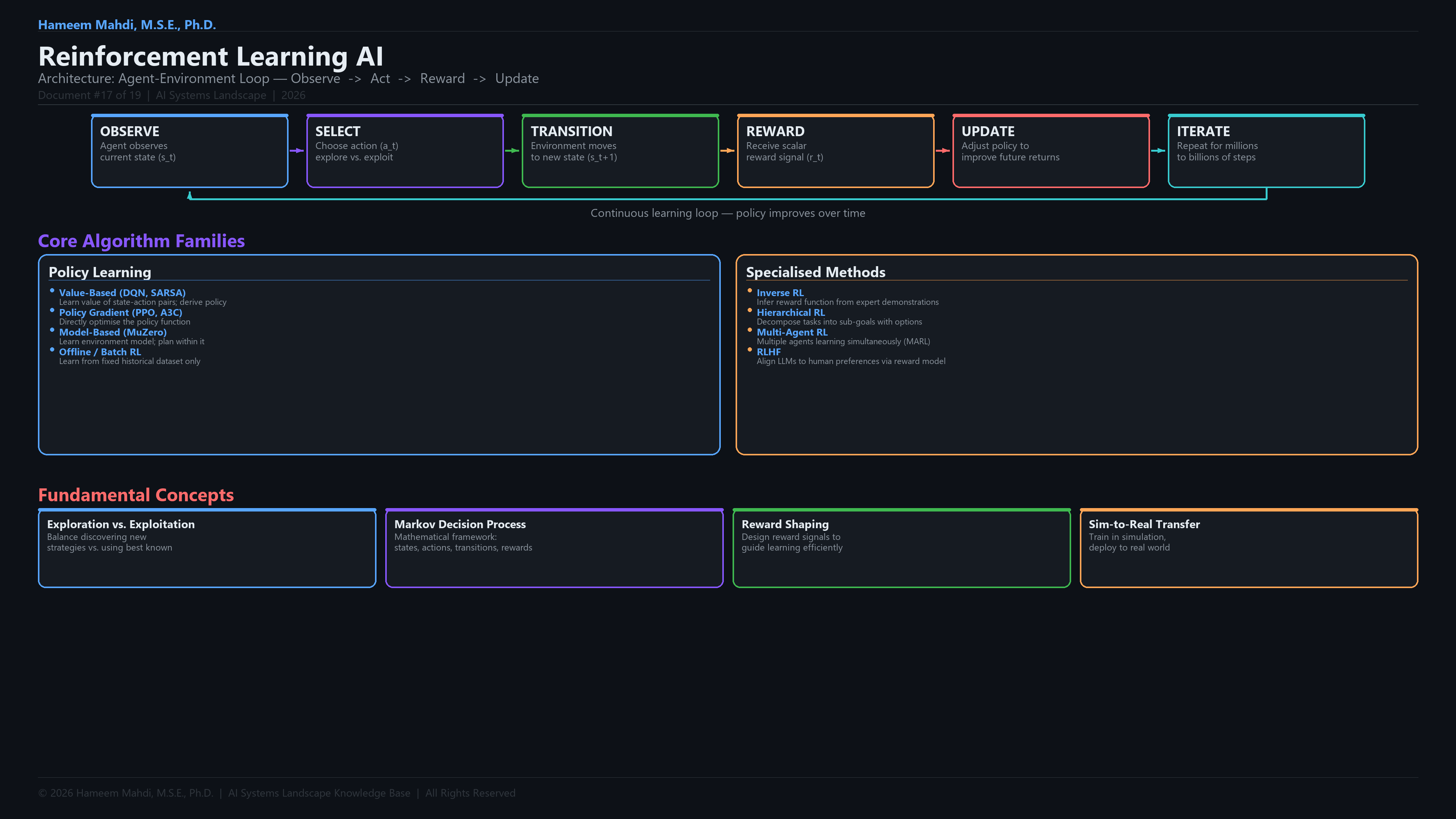
Q-LearningOff-policy algorithm learning the value of state-action pairs to find optimal policies.
DQNDeep Q-Network — combines Q-learning with deep neural networks for high-dimensional state spaces.
PPOProximal Policy Optimization — stable policy gradient method with clipped objective for reliable training.
Actor-CriticArchitecture with separate policy (actor) and value (critic) networks for reduced variance.
Exploration vs ExploitationFundamental trade-off between trying new actions (explore) and using known good actions (exploit).
Epsilon-GreedyExploration strategy choosing random actions with probability ε, greedy actions otherwise.
RLHFReinforcement Learning from Human Feedback — training reward models from human preferences for LLM alignment.
Sim-to-RealTransferring RL policies trained in simulation to physical environments.
Multi-Agent RLMultiple agents learning simultaneously in a shared environment, with cooperation or competition.
Model-Based RLRL using a learned world model to plan actions without requiring real environment interactions.
Offline RLLearning policies from fixed pre-collected datasets without further environment interaction.
Curriculum LearningTraining RL agents on progressively harder tasks to improve learning efficiency.
Reward ShapingModifying the reward function to guide learning without changing the optimal policy.
SACSoft Actor-Critic — off-policy algorithm maximising both reward and entropy for robust exploration.
Temporal DifferenceLearning from the difference between successive value estimates without waiting for episode completion.
Bellman EquationRecursive decomposition of the value function: V(s) = E[r + γV(s')]. Foundation of dynamic programming and temporal-difference methods.
Discount Factor (γ)Scalar between 0 and 1 that weights future rewards relative to immediate rewards. γ = 0 is myopic; γ → 1 values long-term outcomes.
DPO (Direct Preference Optimization)Alternative to RLHF that optimises LLM policies directly from human preference pairs without training an explicit reward model.
Entropy RegularisationAdding a policy entropy bonus to the objective to encourage exploration and prevent premature convergence to deterministic policies.
EpisodeA complete sequence of agent-environment interaction from an initial state to a terminal state (or maximum time step).
Experience ReplayStoring past (s, a, r, s') transitions in a buffer and sampling mini-batches for training. Breaks temporal correlations and improves sample efficiency.
Exploitation vs ExplorationFundamental trade-off between using known high-reward actions (exploit) and trying new actions to discover potentially better strategies (explore).
Markov Decision Process (MDP)Formal mathematical framework for sequential decision-making: states S, actions A, transition function P, reward function R, discount γ.
Off-PolicyLearning from data generated by a different (possibly older) policy. Enables experience replay. Examples: DQN, SAC, TD3.
On-PolicyLearning only from data generated by the current policy. Data is discarded after each update. Examples: PPO, A2C, REINFORCE.
PolicyA mapping from states to actions — either deterministic π(s) → a or stochastic π(a|s) → probability distribution. The core object RL seeks to optimise.
Reward ShapingModifying the reward signal with additional terms to guide learning without changing the optimal policy. Potential-based shaping preserves optimality.
RLHFReinforcement Learning from Human Feedback — using human preference comparisons as the reward signal to align model behaviour with human intent.
Value FunctionExpected cumulative discounted reward from a state V(s) or state-action pair Q(s,a). Guides action selection and policy improvement.