| Algorithm |
A set of rules or statistical procedure a model follows to learn patterns from data |
| AUC-ROC |
Area Under the Receiver Operating Characteristic Curve; measures a classifier's ability to discriminate between classes regardless of threshold |
| Bagging |
Bootstrap aggregating; training multiple models on random data subsets and averaging their predictions to reduce variance |
| Batch Prediction |
Running a trained model over a large dataset at a scheduled time to produce predictions offline |
| Bias (Statistical) |
Systematic error in a model's predictions due to incorrect assumptions in the learning algorithm |
| Bias (Ethical) |
Unfair, discriminatory, or unrepresentative patterns in model predictions affecting demographic groups |
| Boosting |
Sequential ensemble method where each model corrects the errors of its predecessor; e.g., XGBoost, LightGBM |
| Calibration |
The degree to which a model's predicted probabilities match actual observed frequencies |
| CatBoost |
Gradient boosting library by Yandex with native categorical feature handling |
| Class Imbalance |
A dataset where one class has far fewer examples than another; common in fraud, rare disease, and anomaly detection |
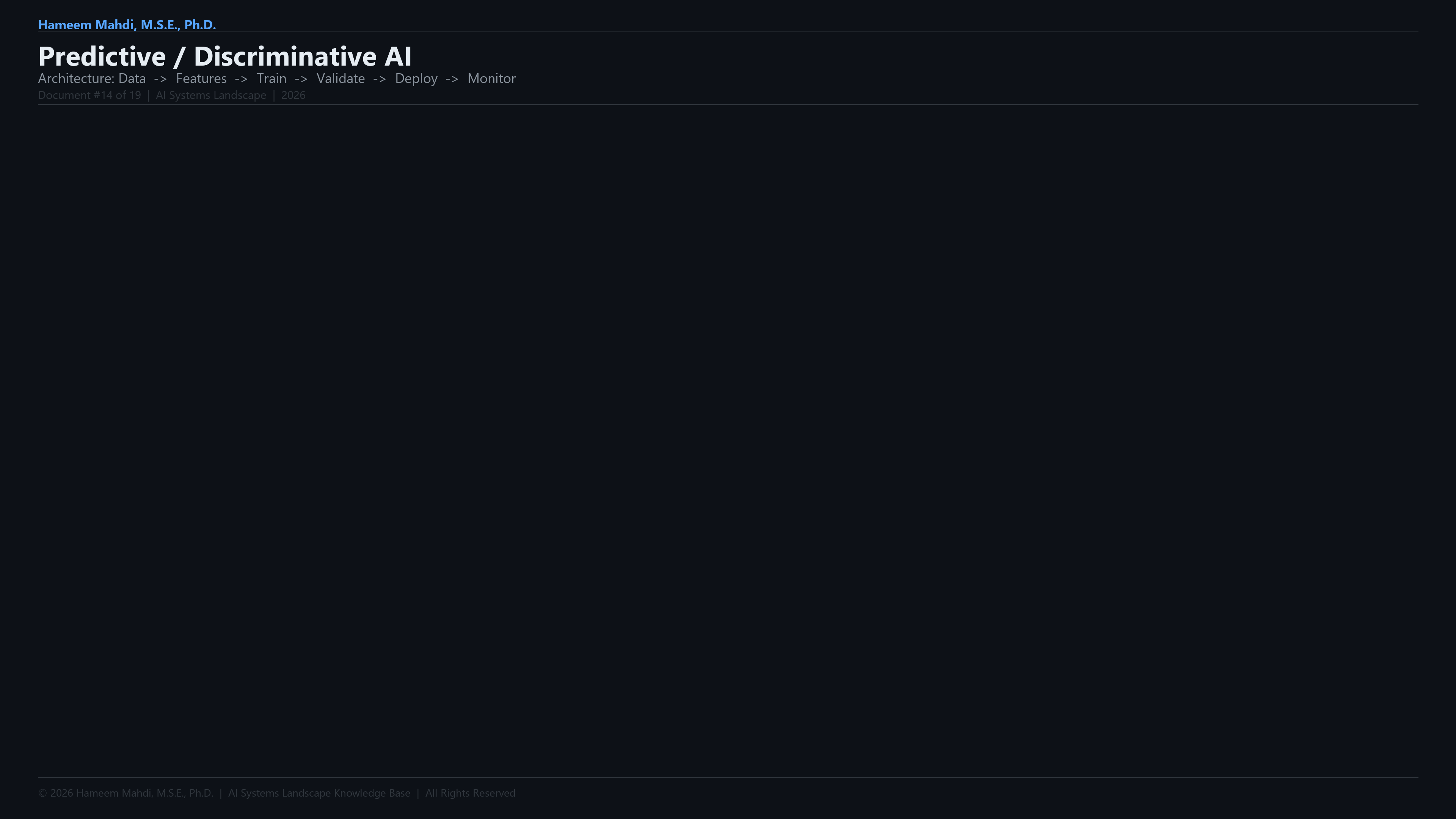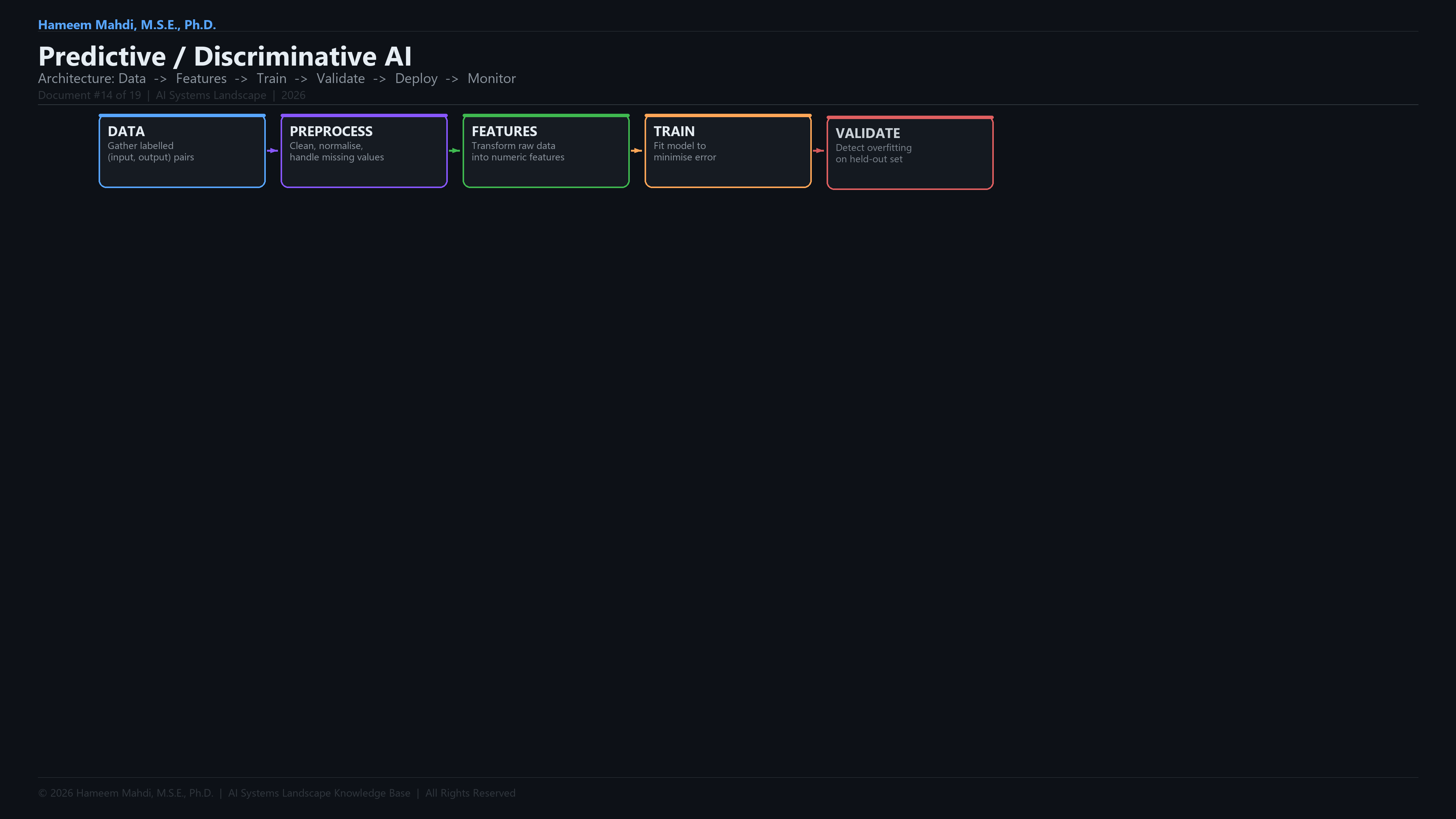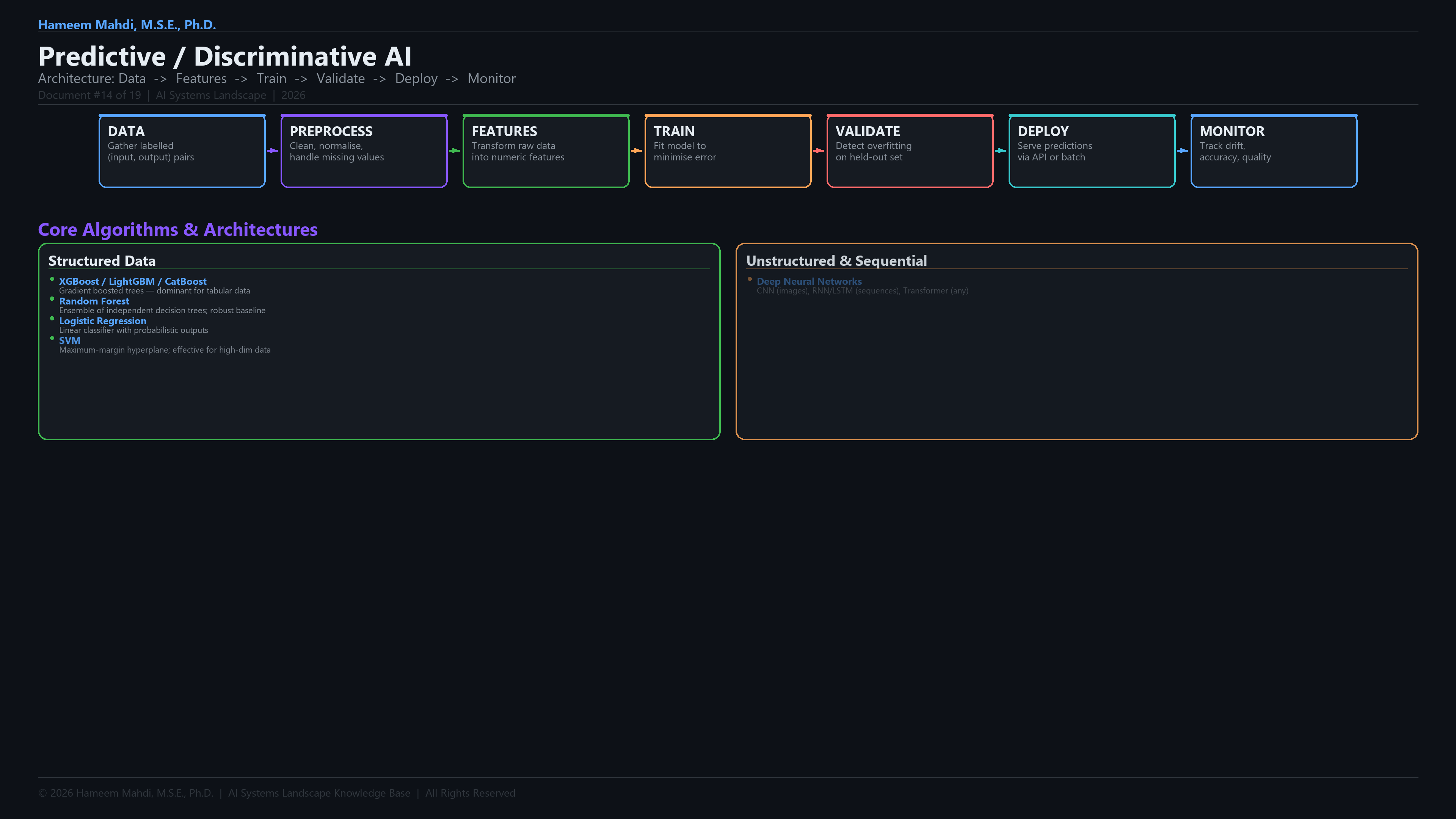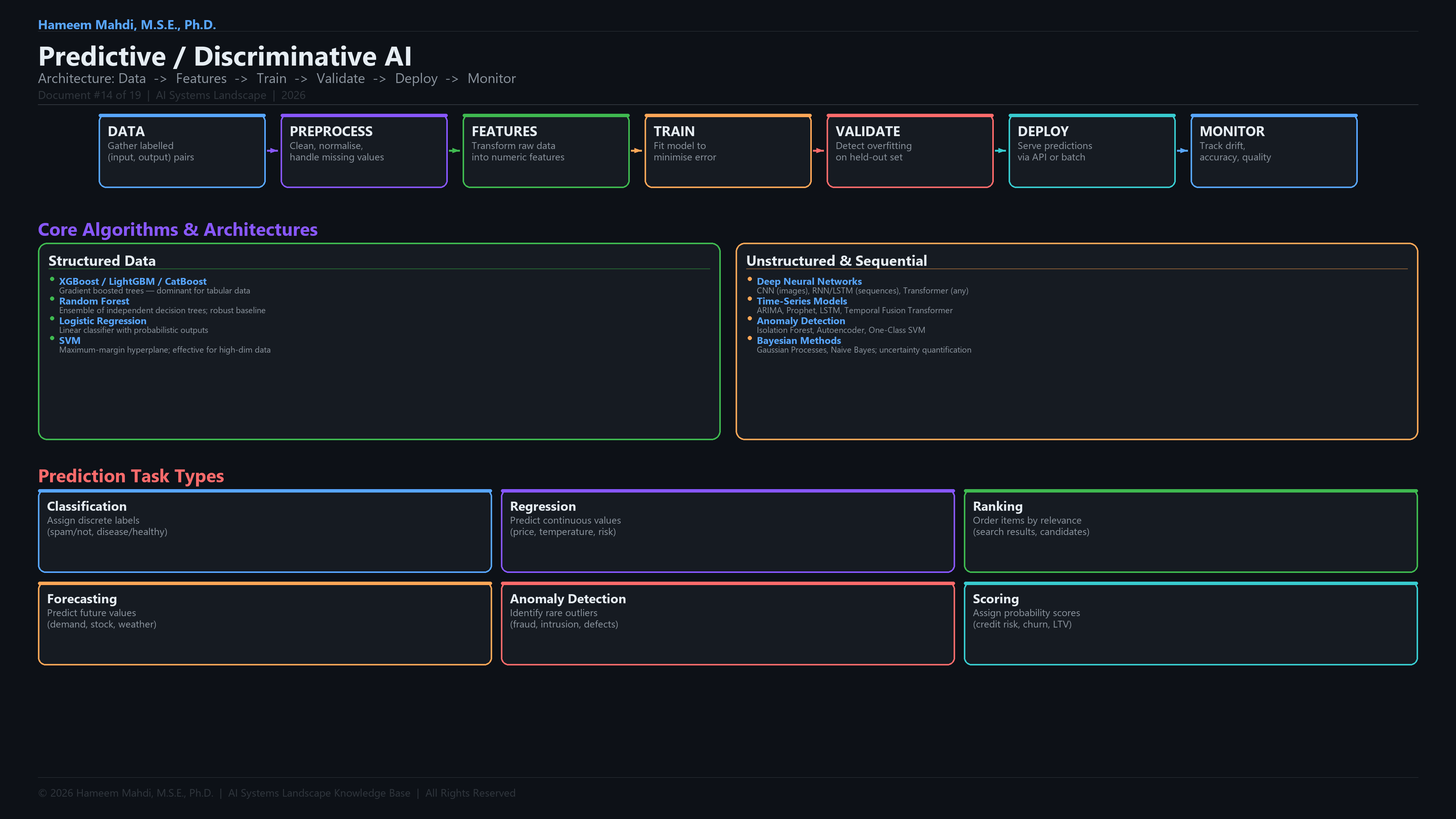
| Classification |
A supervised learning task where the model predicts which discrete category an input belongs to |
| Concept Drift |
When the statistical relationship between features and the target variable changes over time in production |
| Confusion Matrix |
A table showing the counts of true positives, true negatives, false positives, and false negatives for a classifier |
| Cross-Validation |
A technique for evaluating model performance by rotating through multiple train/test splits of the data |
| Data Drift |
When the statistical distribution of input features in production diverges from the training data distribution |
| Data Leakage |
When information from outside the training period or the target itself accidentally enters the feature set, artificially inflating performance |
| Decision Tree |
A model that makes predictions by splitting the data into branches based on feature thresholds |
| Discriminative Model |
A model that directly learns the boundary between classes — P(Y|X) — rather than modelling the full data distribution |
| Embeddings |
Dense, low-dimensional vector representations of discrete entities (users, products, words) that capture semantic similarity |
| Ensemble |
A combination of multiple models whose predictions are aggregated to improve accuracy and robustness |
| F1 Score |
The harmonic mean of precision and recall; the standard metric for imbalanced classification tasks |
| Feature |
An individual measurable property or input variable used by a model to make predictions |
| Feature Engineering |
The process of creating, transforming, and selecting input variables to improve model performance |
| Feature Importance |
A measure of how much each feature contributes to a model's predictions |
| Feature Store |
A centralised infrastructure layer for computing, storing, and serving ML features consistently across training and inference |
| Gradient Descent |
An optimization algorithm that iteratively adjusts model parameters in the direction of the steepest decrease in the loss function |
| Hyperparameter |
A model configuration setting (e.g., learning rate, tree depth) set before training and not learned from data |
| Hyperparameter Optimization (HPO) |
The process of systematically searching for the best hyperparameter values to maximise model performance |
| Inference |
The process of applying a trained model to new, unseen data to generate predictions |
| Isolation Forest |
An unsupervised anomaly detection algorithm that isolates anomalies by randomly partitioning the feature space |
| K-Fold Cross-Validation |
Splitting data into k equal folds; training on k-1 folds and validating on the remaining one, rotated k times |
| Label |
The known correct output for a training example; also called the target variable or ground truth |
| LightGBM |
Microsoft's gradient boosting framework; optimised for speed and large datasets via leaf-wise tree growth |
| Logistic Regression |
A linear classification model that outputs class probabilities via a sigmoid or softmax function |
| Loss Function |
A mathematical function that measures the difference between the model's predictions and the true labels; minimised during training |
| MAE (Mean Absolute Error) |
The average absolute difference between predicted and actual values in a regression task |
| MLOps |
Machine Learning Operations; the discipline of deploying, monitoring, and maintaining ML models in production |
| Model Card |
A standardised document summarising a model's intended use, performance characteristics, limitations, and ethical considerations |
| Model Drift |
The degradation of a deployed model's predictive performance over time as real-world patterns evolve |
| Model Registry |
A centralised repository for storing, versioning, and managing trained ML model artefacts |
| Normalisation |
Scaling numeric features to a standard range (e.g., [0,1]) so that features with different scales do not dominate the model |
| Overfitting |
When a model learns the noise and idiosyncrasies of training data so well that it fails to generalise to new data |
| Precision |
The fraction of positive predictions that are actually correct: TP / (TP + FP) |
| Predictive Maintenance |
Using ML models to predict when equipment will fail so maintenance can be proactively scheduled |
| Propensity Model |
A model that estimates the probability that an individual will take a specific action (purchase, churn, respond) |
| Random Forest |
An ensemble of decision trees trained on random subsets of data and features; predictions are aggregated by voting |
| Real-Time Inference |
Serving model predictions via an API in response to live requests, typically with sub-100ms latency |
| Recall |
The fraction of actual positives correctly identified by the model: TP / (TP + FN); also called sensitivity |
| Regression |
A supervised learning task where the model predicts a continuous numeric value |
| Regularisation |
Techniques (L1/L2 penalty, dropout) that constrain model complexity to reduce overfitting |
| RMSE (Root Mean Squared Error) |
The square root of the average squared prediction error; the standard regression metric |
| Risk Score |
A numeric probability or index output by a model representing the likelihood of a specific risk event |
| SHAP (SHapley Additive exPlanations) |
A game-theory-based method for explaining how each feature contributed to a specific model prediction |
| SMOTE |
Synthetic Minority Over-sampling Technique; generates synthetic minority class examples to address class imbalance |
| Supervised Learning |
A learning paradigm where models are trained on (input, label) pairs with the goal of predicting the label for new inputs |
| SVM (Support Vector Machine) |
A classification algorithm that finds the maximum-margin hyperplane separating two classes in feature space |
| Target Encoding |
Replacing a categorical variable with the mean of the target variable for that category; useful for high-cardinality features |
| Transfer Learning |
Fine-tuning a pre-trained model on a new, smaller, domain-specific dataset |
| Underfitting |
When a model is too simple to capture the real patterns in data; exhibits high bias and low variance |
| Uplift Modelling |
A technique that models the incremental effect of a treatment (e.g., marketing contact) on an individual's behaviour |
| Validation Set |
A held-out subset of training data used to evaluate model performance and tune hyperparameters during development |
| Variance (Statistical) |
The sensitivity of a model's predictions to fluctuations in the training data; high variance leads to overfitting |
| Walk-Forward Validation |
A time-series cross-validation strategy where the model is trained on past data and validated on the next future window |
| XGBoost |
Extreme Gradient Boosting; a regularised gradient boosting framework; dominant on tabular ML tasks and Kaggle competitions |