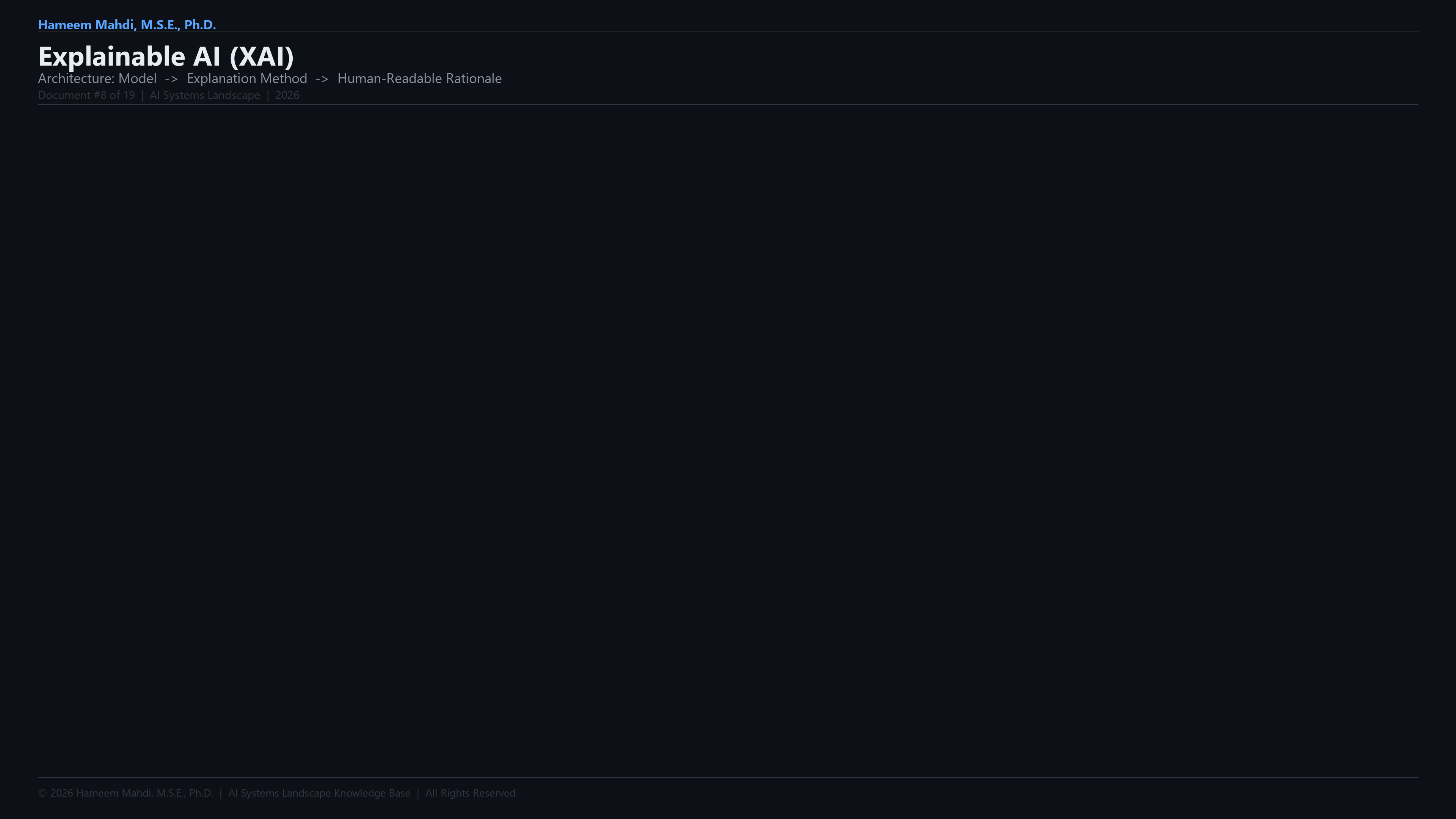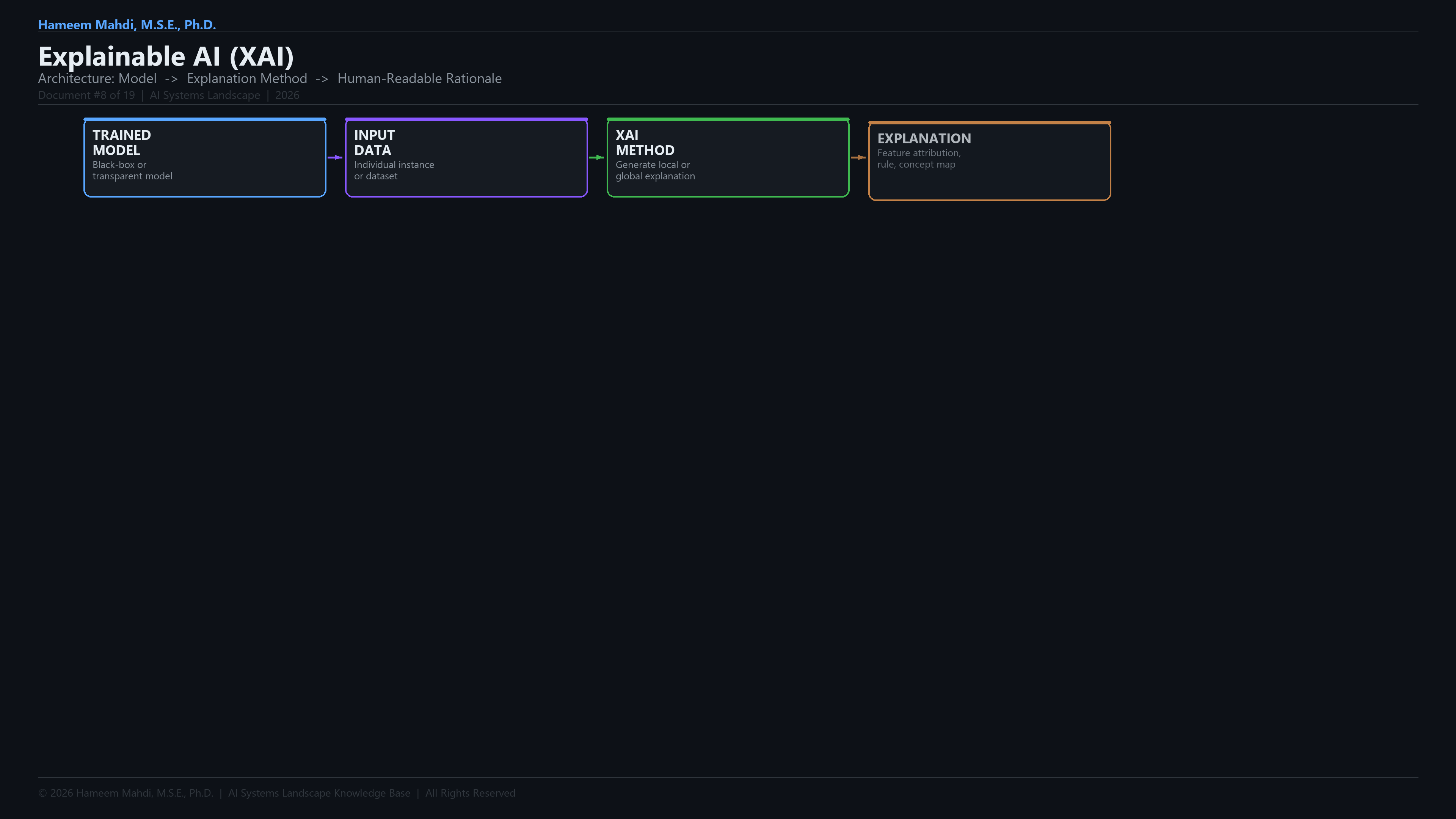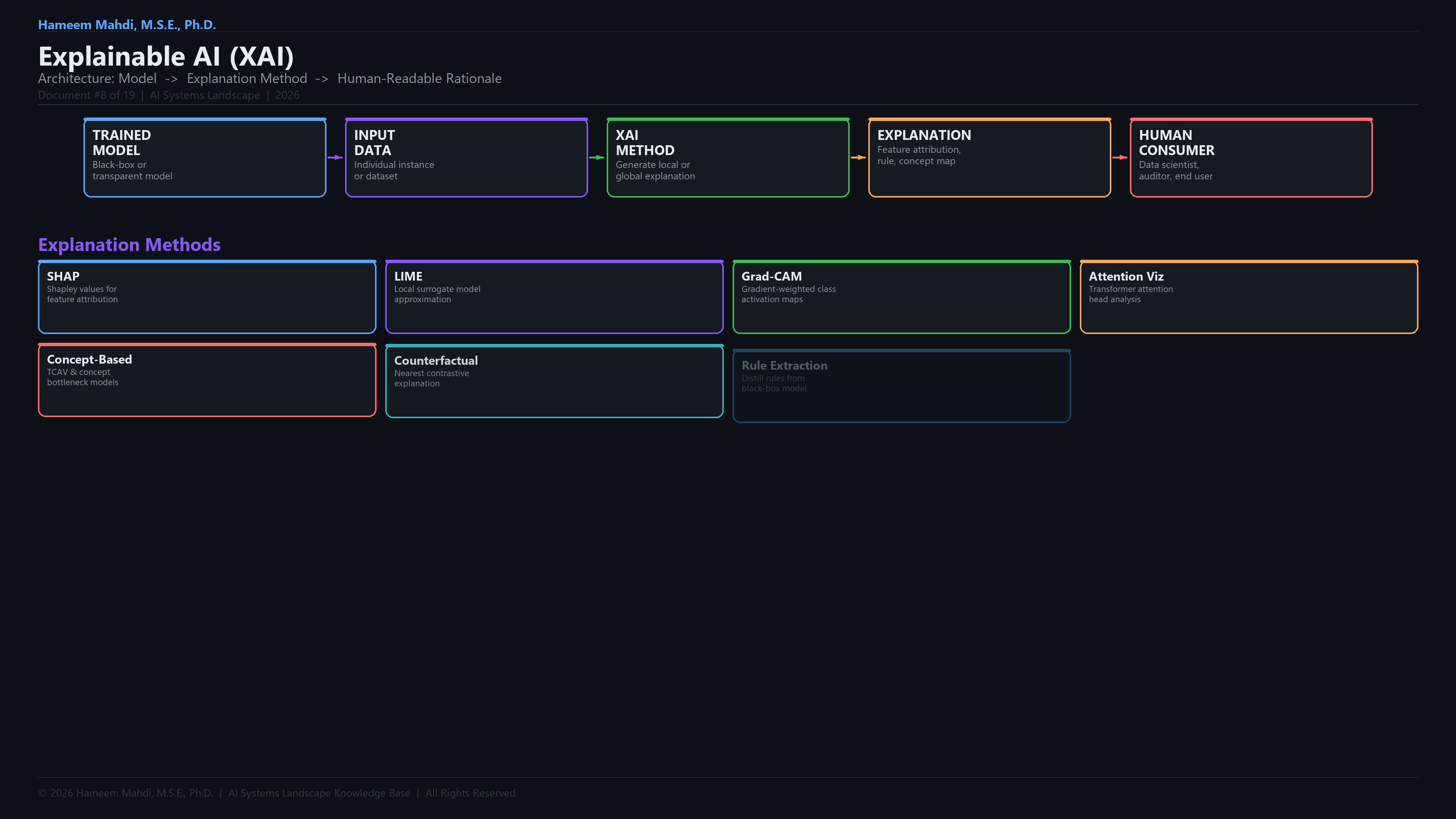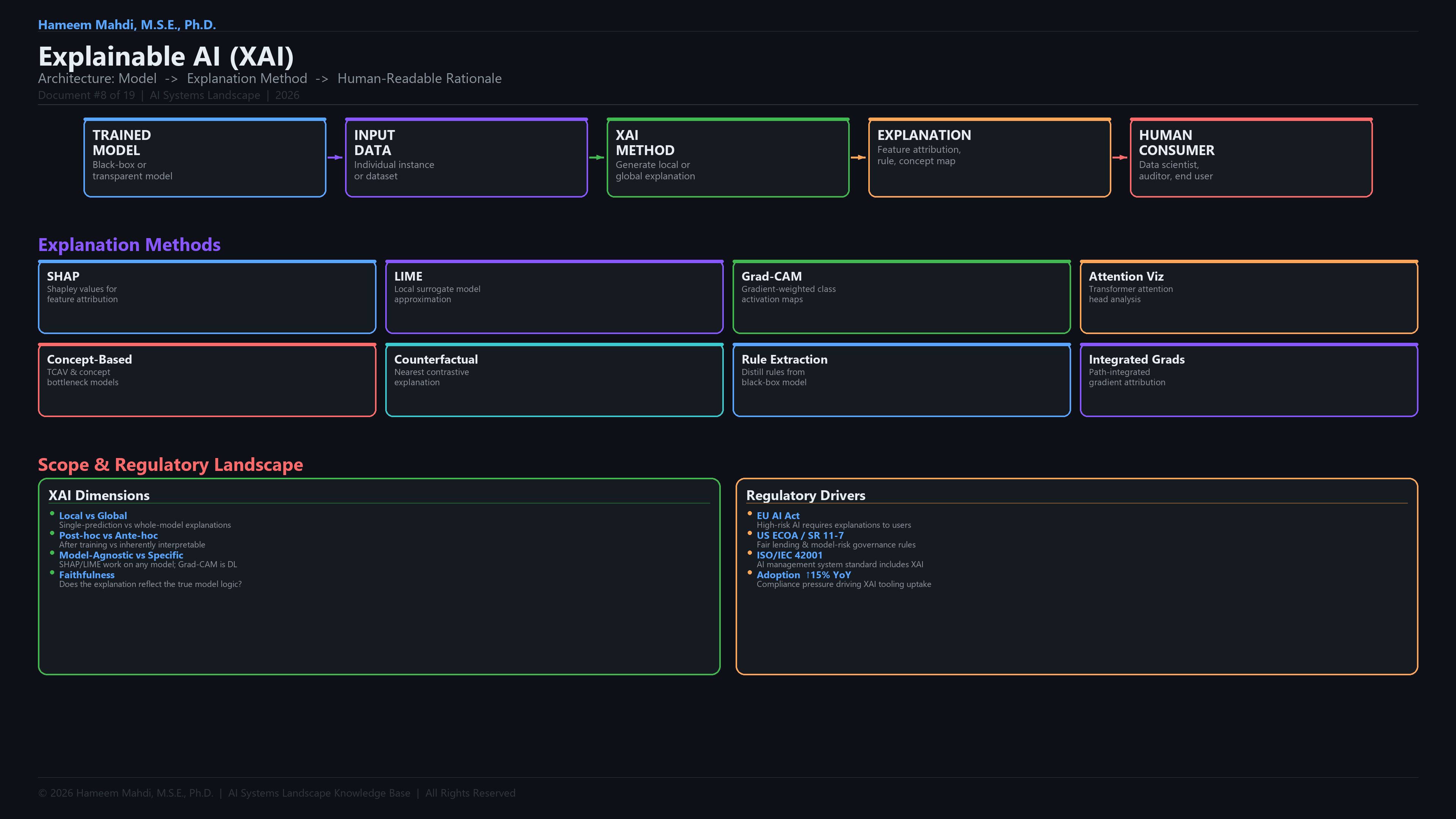
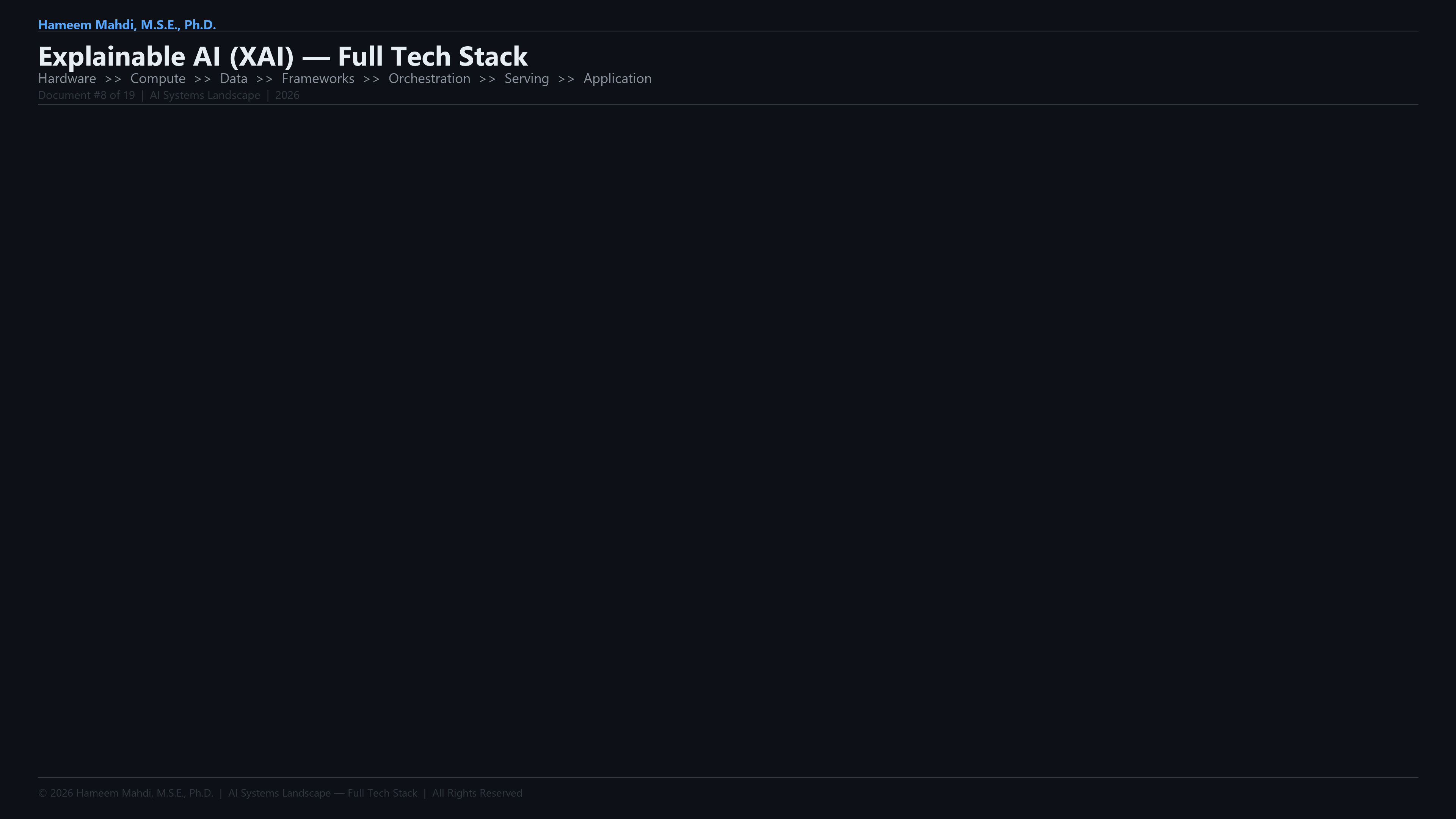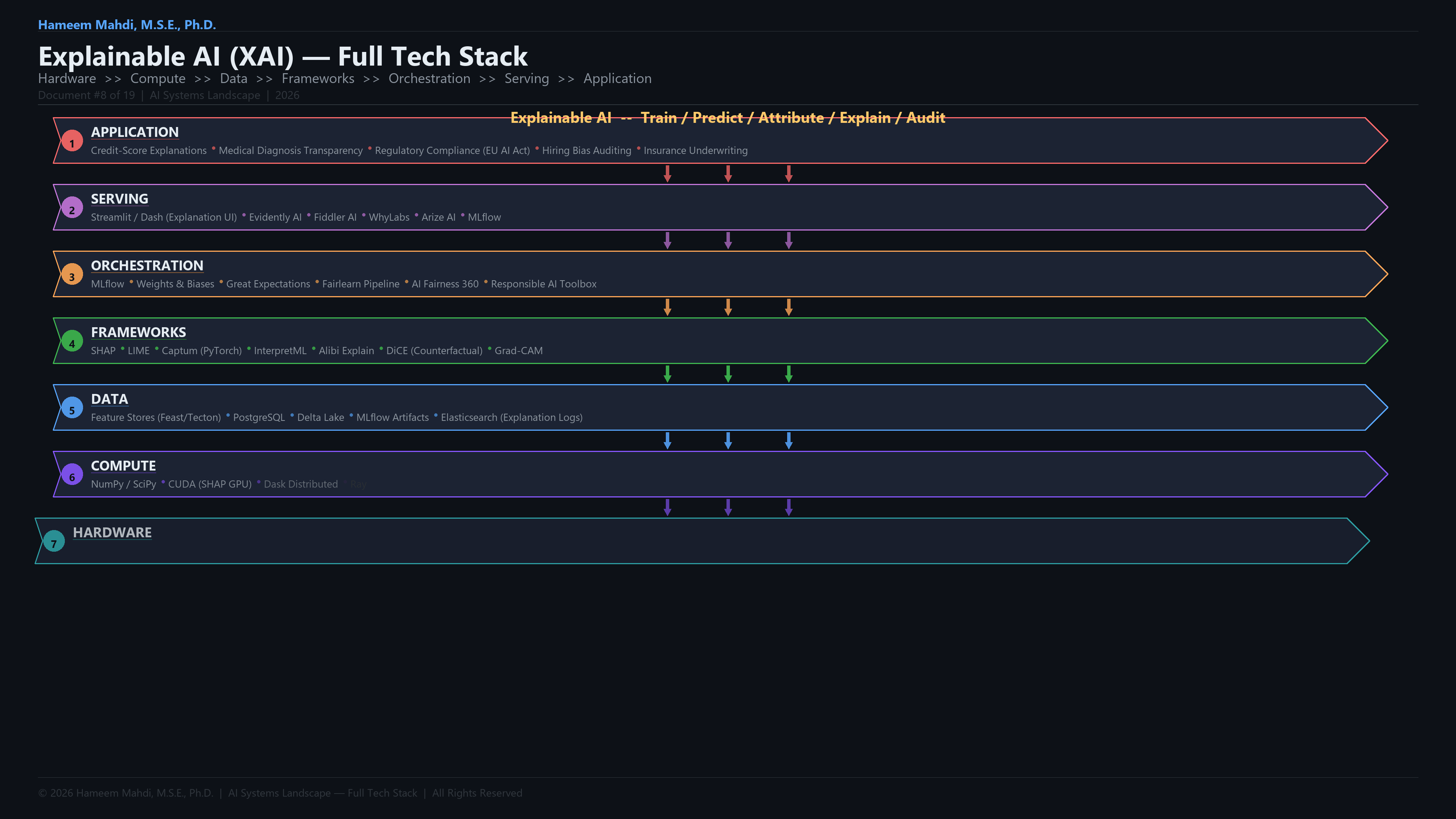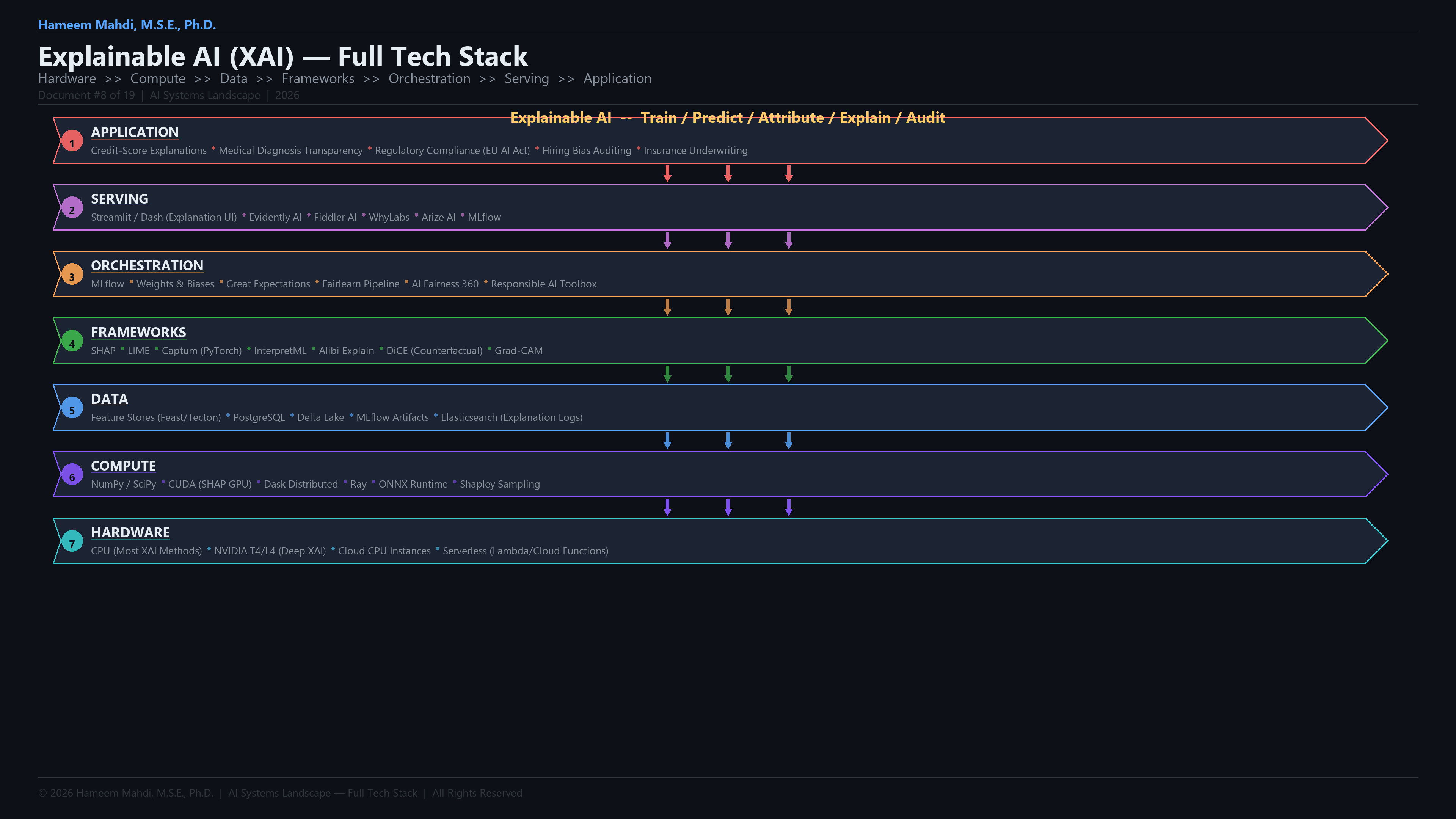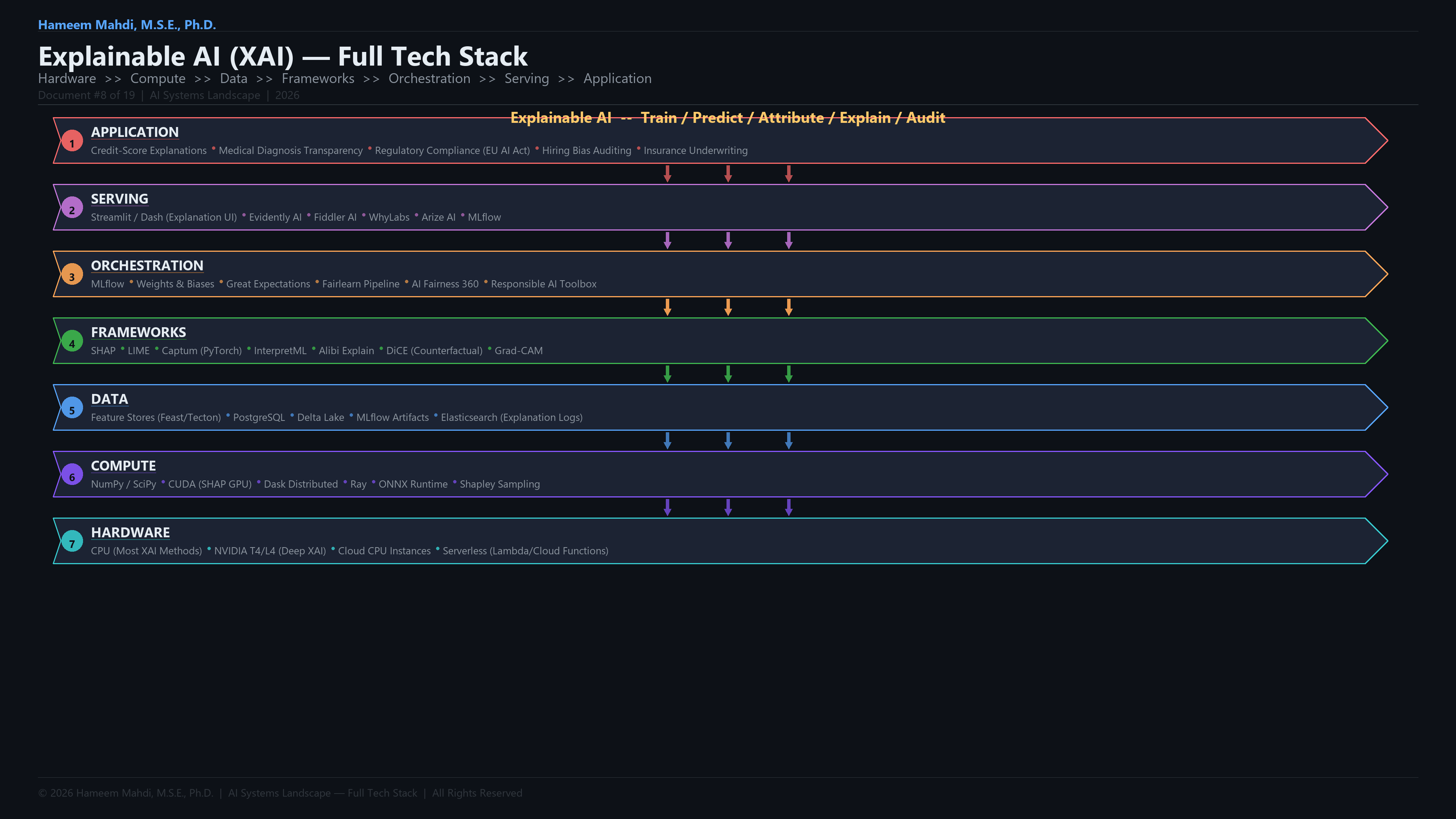
| Explainable AI (XAI) |
Makes AI decisions understandable to humans |
SHAP explaining a loan denial |
| Agentic AI |
Pursues goals autonomously with tools, memory, and planning |
Research agent, coding agent |
| Analytical AI |
Extracts insights from data |
Anomaly detector, clustering |
| Autonomous AI (Non-Agentic) |
Operates independently within fixed boundaries without human input |
Autopilot, auto-scaling, algorithmic trading |
| Bayesian / Probabilistic AI |
Reasons under uncertainty using probability distributions |
Clinical trial analysis, A/B testing, risk modelling |
| Cognitive / Neuro-Symbolic AI |
Combines neural learning with symbolic reasoning |
LLM + knowledge graph, physics-informed neural net |
| Conversational AI |
Manages multi-turn dialogue between humans and machines |
Customer service chatbot, voice assistant |
| Evolutionary / Genetic AI |
Optimises solutions through population-based search inspired by natural selection |
Neural architecture search, logistics scheduling |
| Generative AI |
Creates new content from learned patterns |
LLM, image generator |
| Multimodal Perception AI |
Fuses vision, language, audio, and other modalities |
GPT-4o processing image + text, AV sensor fusion |
| Optimization / Operations Research AI |
Finds optimal solutions to constrained mathematical problems |
Vehicle routing, supply chain planning, scheduling |
| Physical / Embodied AI |
Acts in the physical world through sensors and actuators |
Autonomous vehicle, robot arm, drone |
| Predictive / Discriminative AI |
Classifies or forecasts from data |
Fraud detection model |
| Privacy-Preserving AI |
Trains and runs AI without exposing raw data |
Federated learning, differential privacy |
| Reactive AI |
Responds to current input with no memory or learning |
Thermostat, ABS braking system |
| Recommendation / Retrieval AI |
Surfaces relevant items from large catalogues based on user signals |
Netflix suggestions, Google Search, Spotify playlists |
| Reinforcement Learning AI |
Learns optimal behaviour from reward signals via trial and error |
AlphaGo, robotic locomotion, RLHF |
| Scientific / Simulation AI |
Solves scientific problems and models physical systems |
AlphaFold, climate simulation, molecular dynamics |
| Symbolic / Rule-Based AI |
Reasons over explicit rules and knowledge to derive conclusions |
Medical expert system, legal reasoning engine |