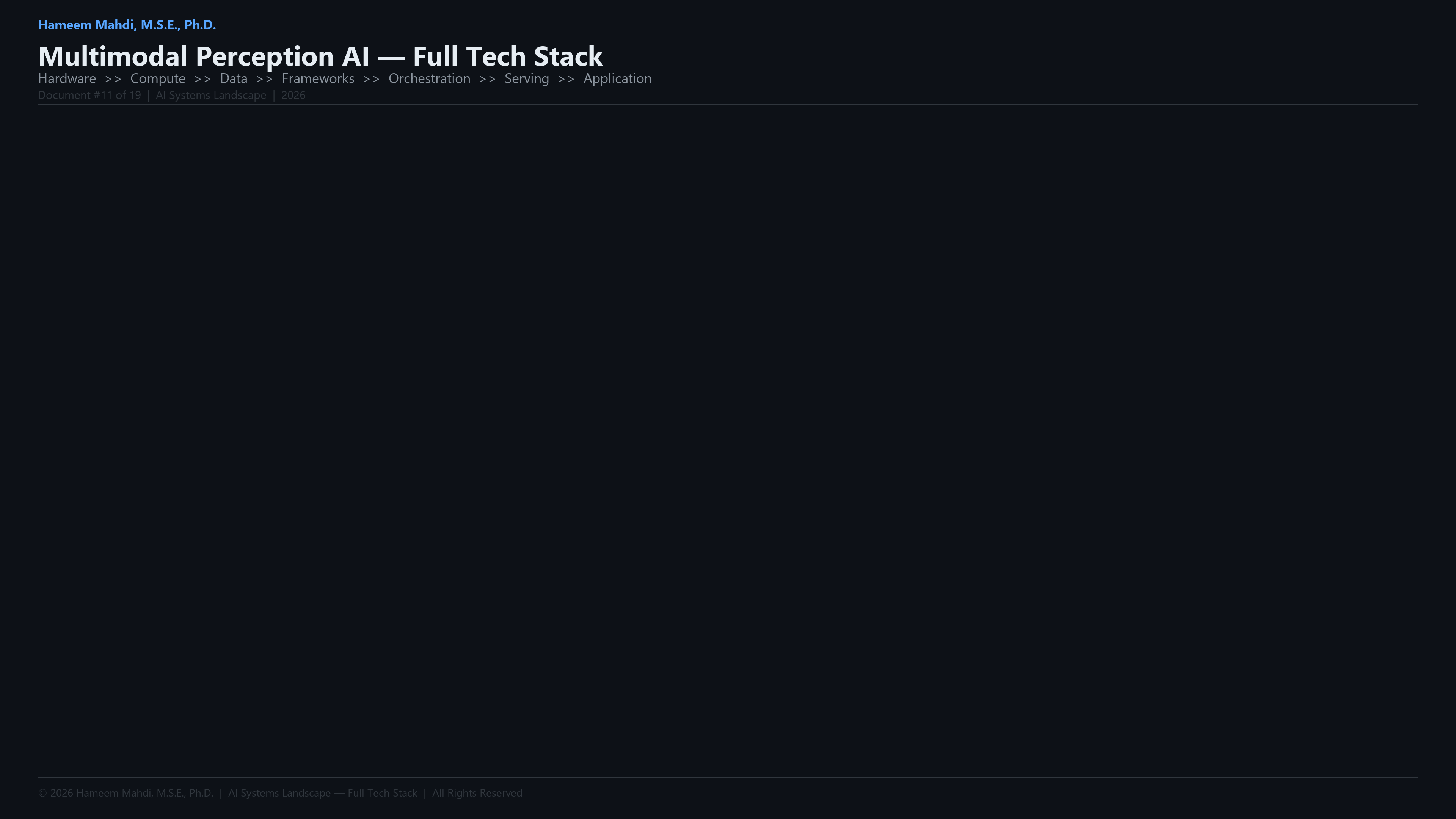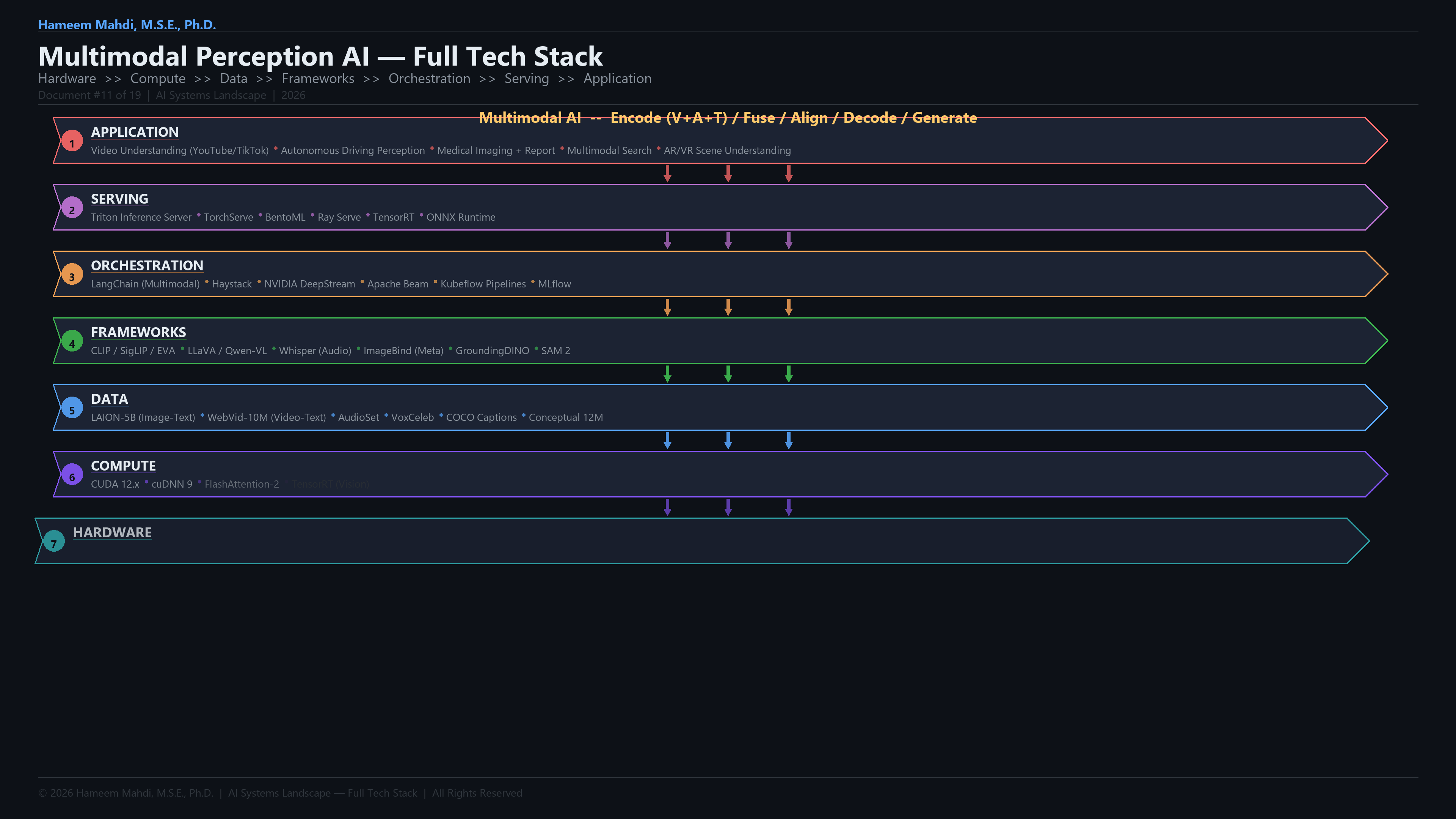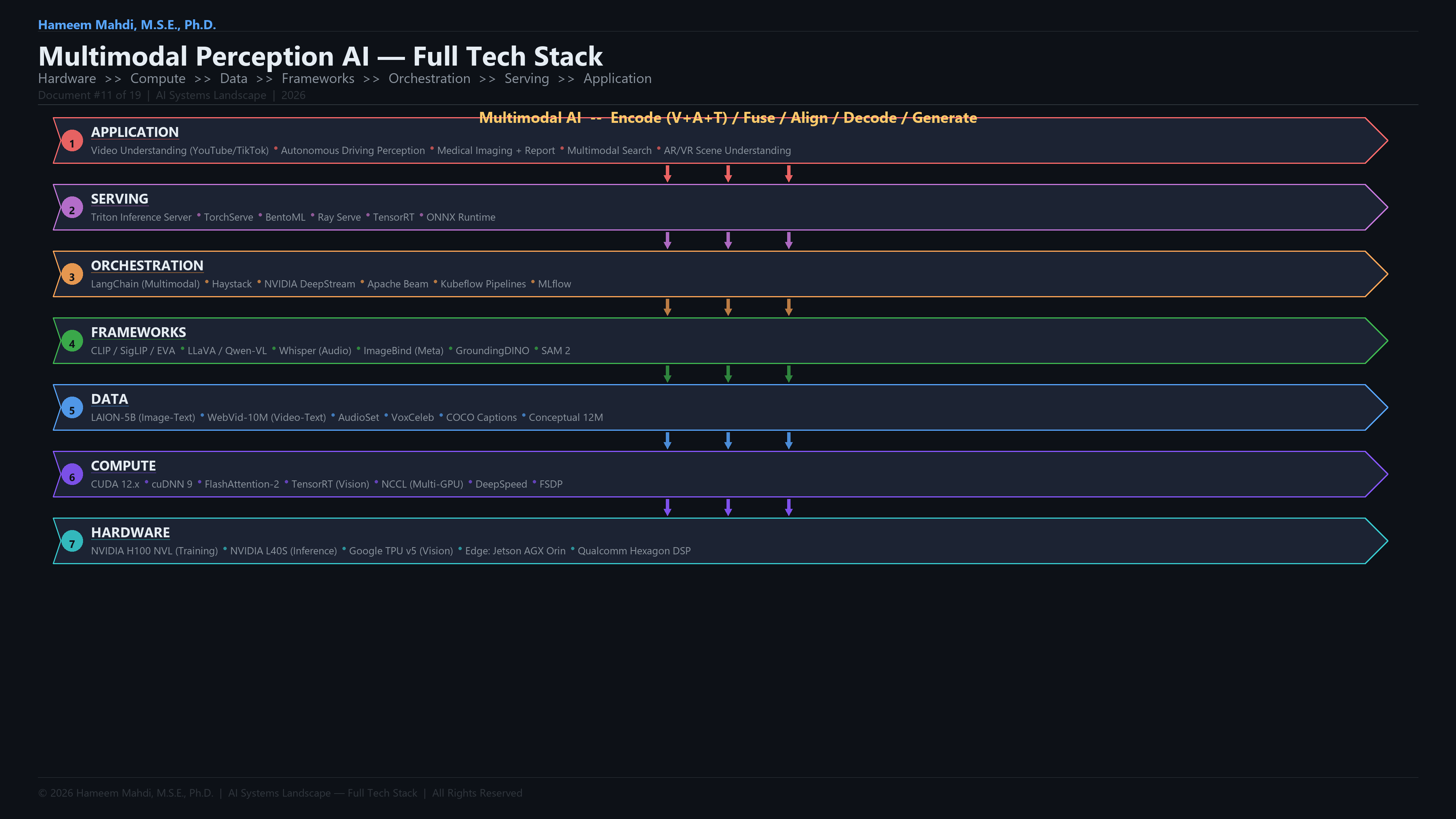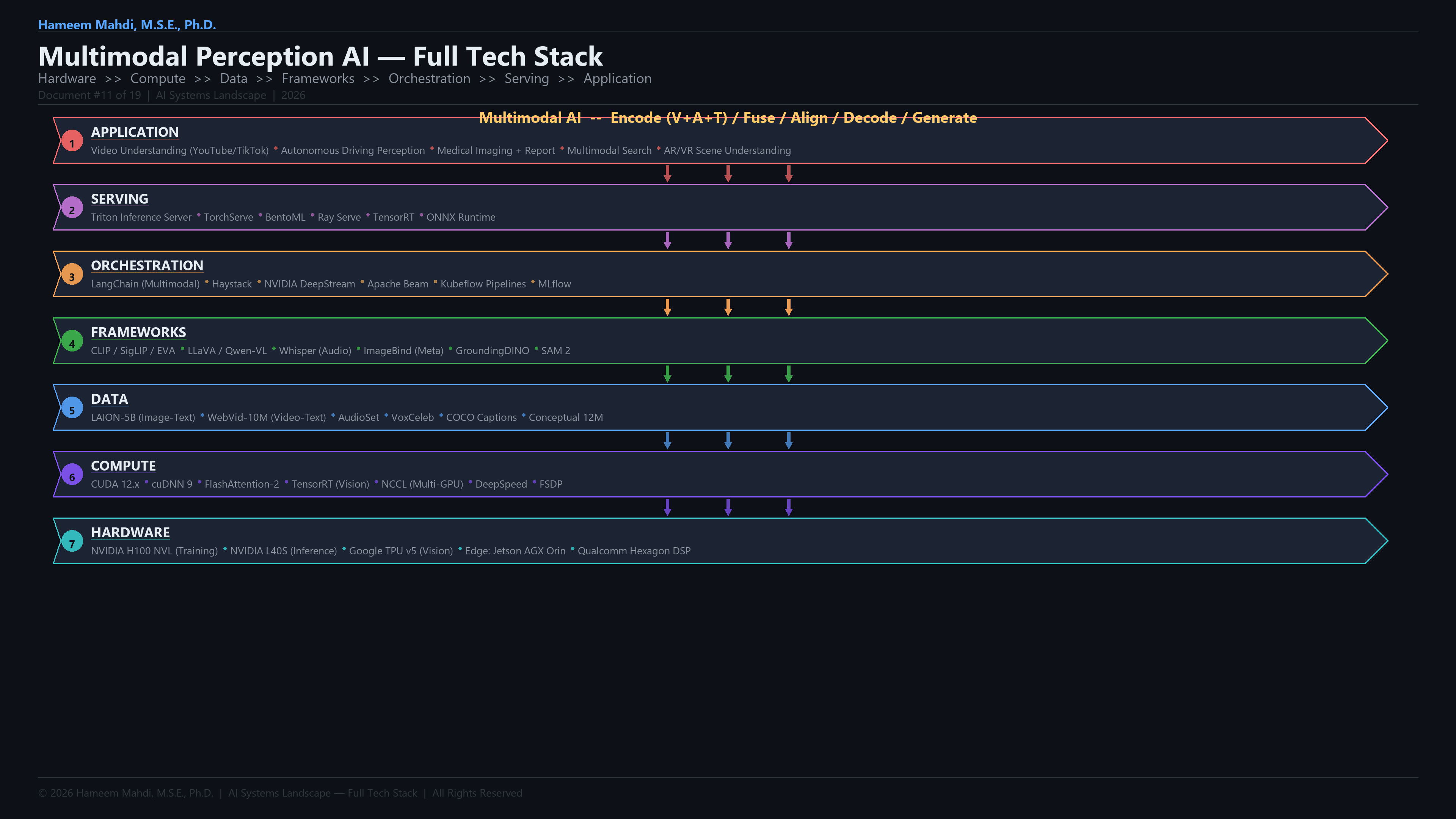
Key terms in multimodal perception AI.
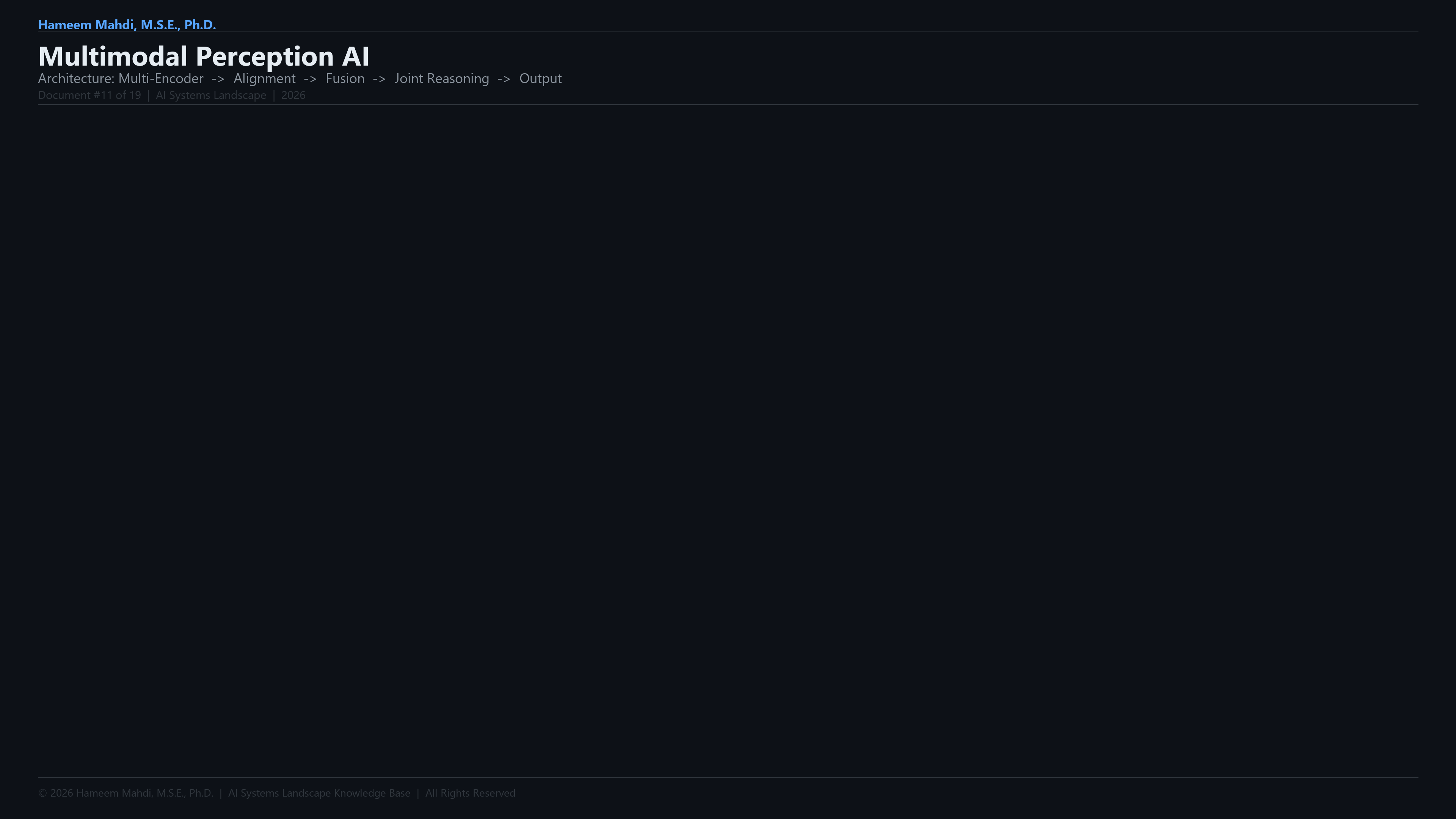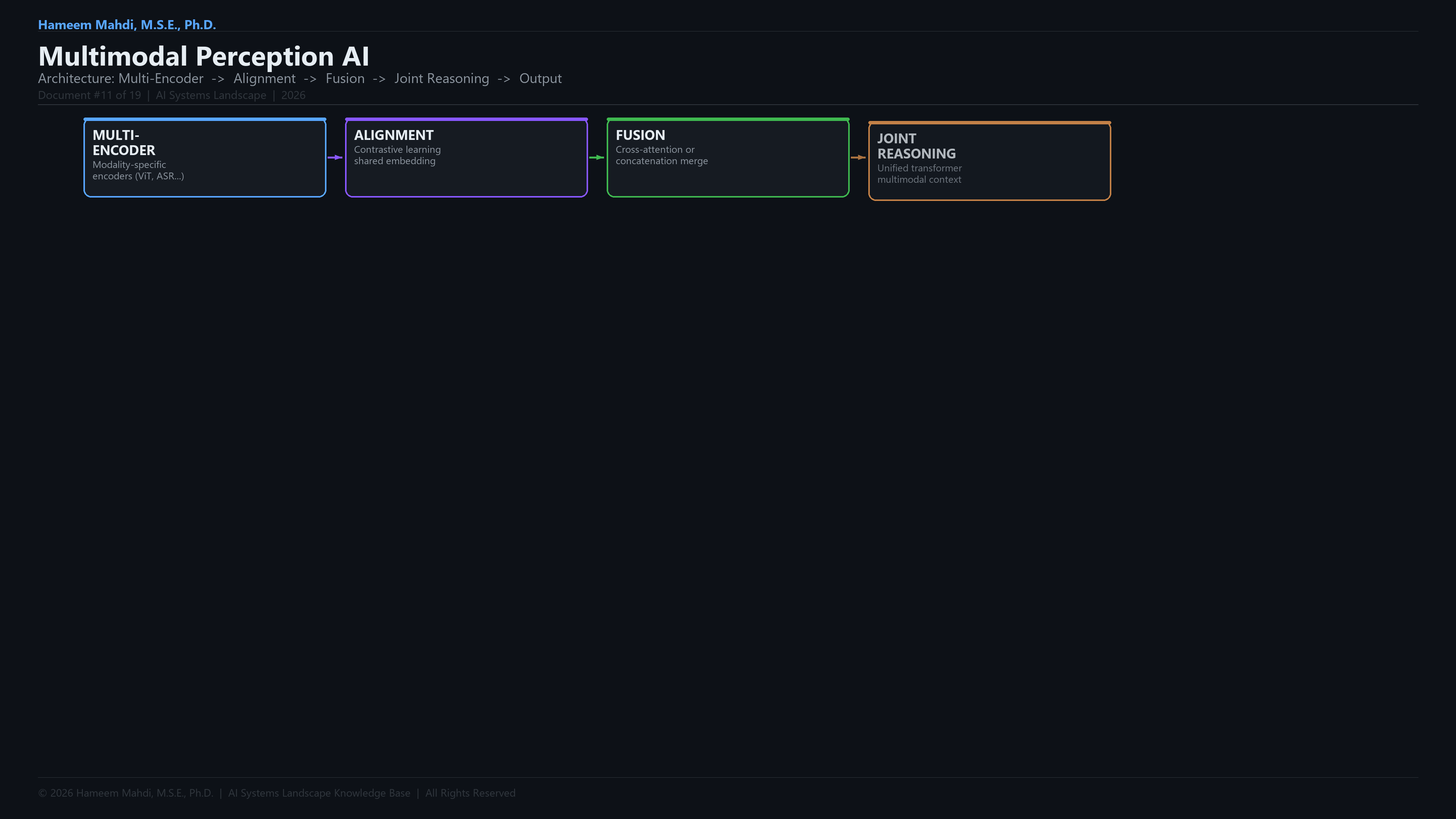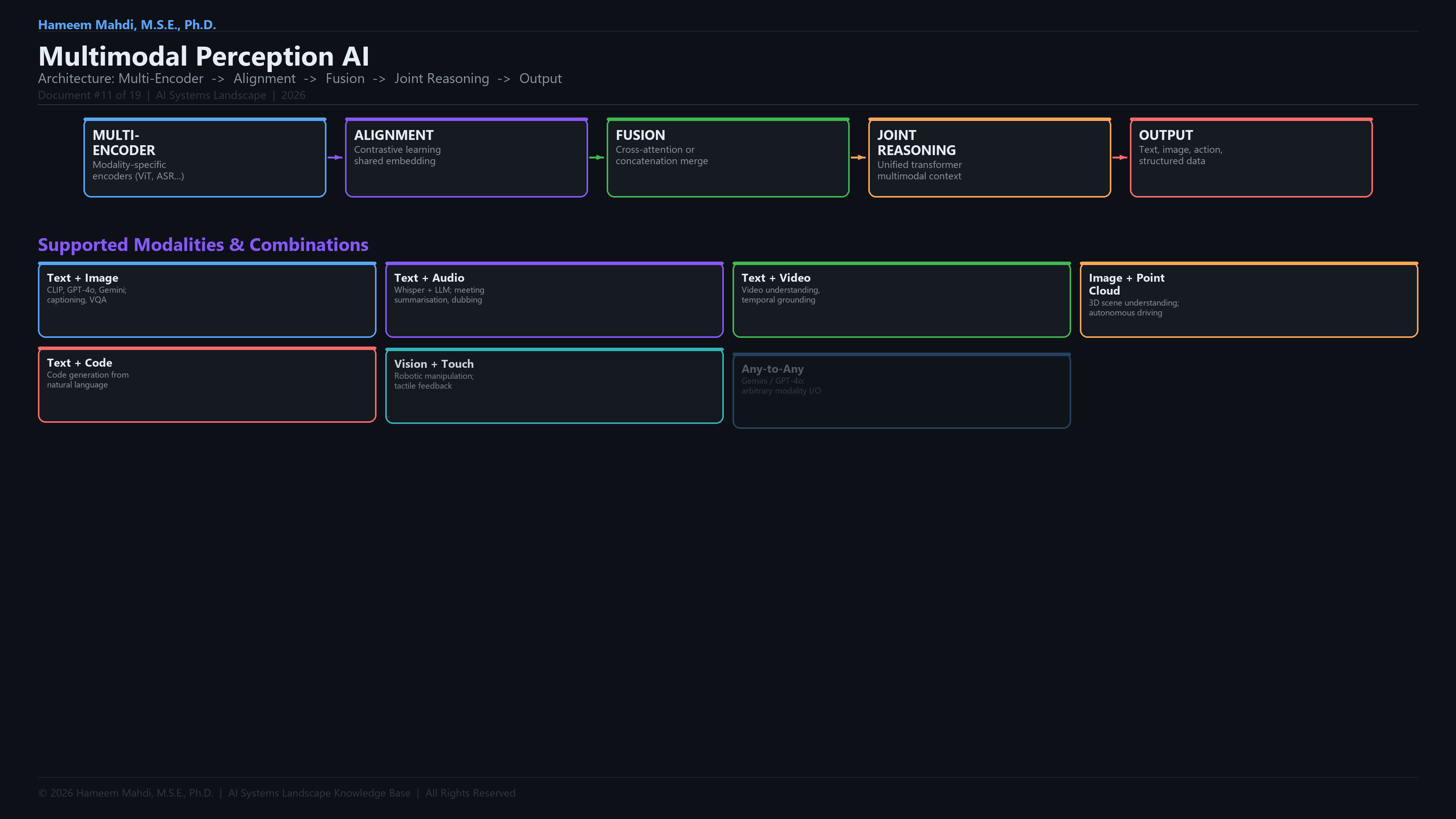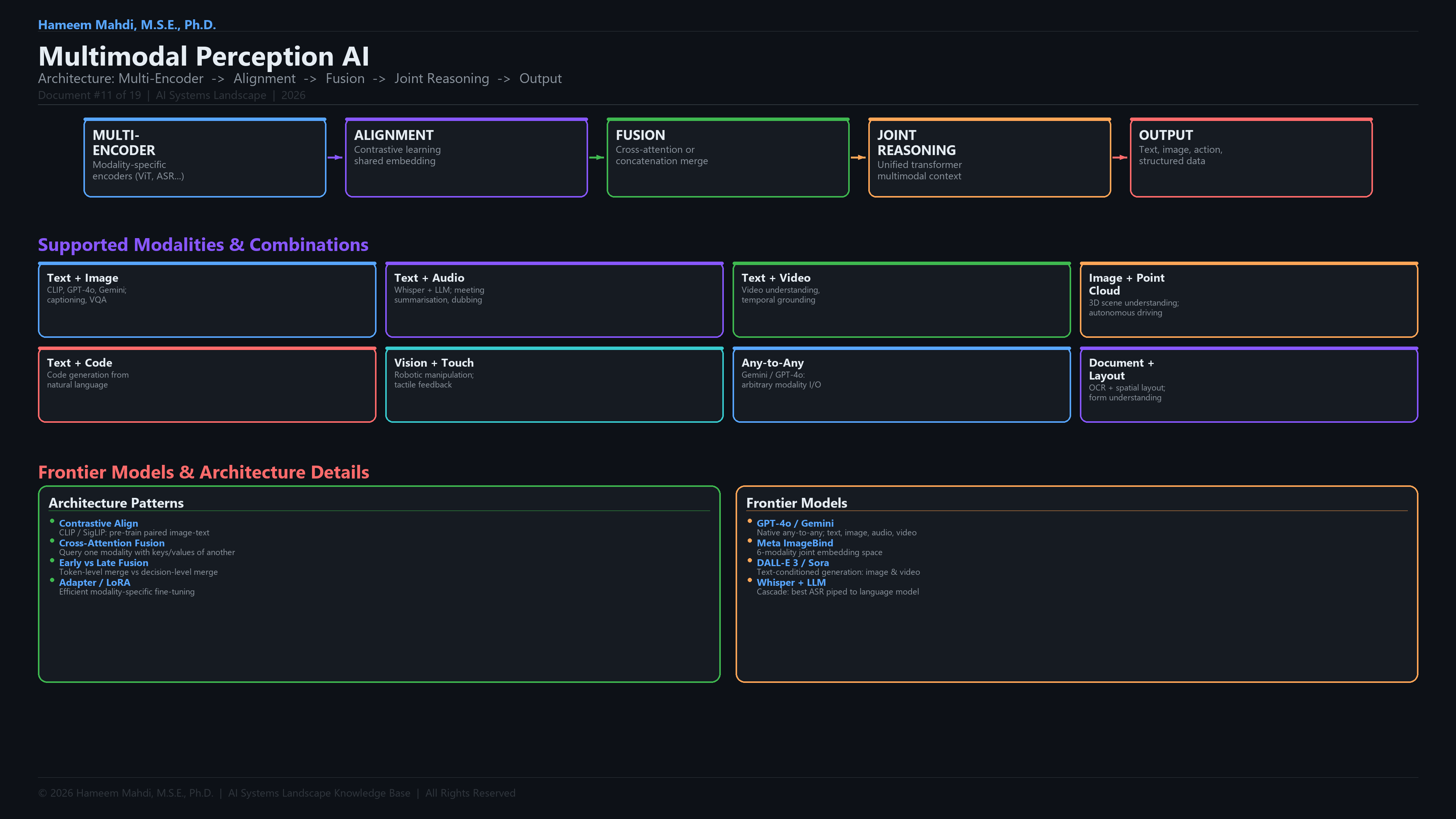
AlignmentThe process of projecting embeddings from different modalities into a shared vector space so they can be compared and fused.
Vision-Language ModelModel jointly processing visual and textual information for tasks like VQA, captioning, and reasoning.
Sensor FusionCombining data from multiple sensor modalities (camera, LiDAR, radar) for robust perception.
Cross-Modal AttentionAttention mechanism where queries from one modality attend to keys/values from another.
CLIPContrastive Language-Image Pre-training — aligning image and text embeddings in a shared space.
Any-to-Any ModelArchitecture accepting and generating arbitrary combinations of modalities (text, image, audio, video).
Modality AlignmentProcess of mapping different modalities into a shared representation space.
Visual Question AnsweringTask of answering natural language questions about the content of images.
Image CaptioningGenerating natural language descriptions of image content.
GroundingLinking language to specific regions or objects in visual input.
Contrastive LearningSelf-supervised learning by pulling similar pairs together and pushing dissimilar pairs apart in embedding space.
Depth EstimationPredicting per-pixel distance from the camera, enabling 3D understanding from 2D images.
Optical FlowEstimating per-pixel motion vectors between consecutive video frames.
Audio-Visual LearningModels that jointly process audio and visual signals for tasks like lip reading or sound source localisation.
Tokenisation (Visual)Converting image patches into discrete tokens for processing by transformer architectures.
Embedding SpaceHigh-dimensional vector space where semantically similar items from any modality are nearby.
Any-to-Any ModelA single model capable of accepting and producing arbitrary combinations of modalities (text, image, audio, video). Examples: GPT-4o, Gemini 2.0.
BEV (Bird’s Eye View)A top-down 2D projection of 3D sensor data onto a ground plane grid, widely used in autonomous vehicle perception for unified multi-sensor fusion.
Bottleneck TokensLearnable latent query vectors that compress information from multiple modalities into a fixed-size representation. Used in Perceiver and Flamingo architectures.
CLIPContrastive Language-Image Pre-training. A model that learns aligned image-text embeddings via contrastive learning, enabling zero-shot visual classification.
Contrastive LearningA self-supervised training paradigm that pulls matching pairs (e.g., image-caption) closer and pushes non-matching pairs apart in embedding space.
Cross-AttentionA transformer attention mechanism where queries come from one modality and keys/values from another, enabling directed information flow between modalities.
Cross-ModalRelating to or involving interactions between two or more different modalities (e.g., using text to query an image, or audio to ground a video segment).
Early FusionCombining raw or lightly-processed features from all modalities at the input level before any task-specific processing, maximising cross-modal interaction depth.
GroundingLinking linguistic references to specific regions, objects, or segments in another modality (e.g., mapping the phrase “red car” to a bounding box in an image).
Hallucination (VLM)When a vision-language model generates descriptions of objects or details not actually present in the input image, fabricating content from language priors.
Late FusionProcessing each modality independently through separate encoders and combining only the final predictions or high-level features at the decision level.
LiDARLight Detection and Ranging. An active sensor that emits laser pulses to measure distances, producing precise 3D point clouds of the environment.
ModalityA distinct type or channel of input data (e.g., text, image, audio, video, depth, LiDAR, radar, tabular). Each modality has unique statistical properties.
Modality DominanceA training failure mode where the model relies disproportionately on one modality, effectively ignoring informative signals from weaker modalities.